OPTIMIZE TABLE
Optimizing a table in Databend is about compacting or purging its historical data to save storage space and improve query efficiency.
Time Travel Requires Historical Data. Purging historical data from storage might break the Time Travel feature. Take this into consideration before you do so.
What are Snapshot, Segment, and Block?
Snapshot, segment, and block are the concepts Databend uses for data storage. Databend uses them to construct a hierarchical structure for storing table data.
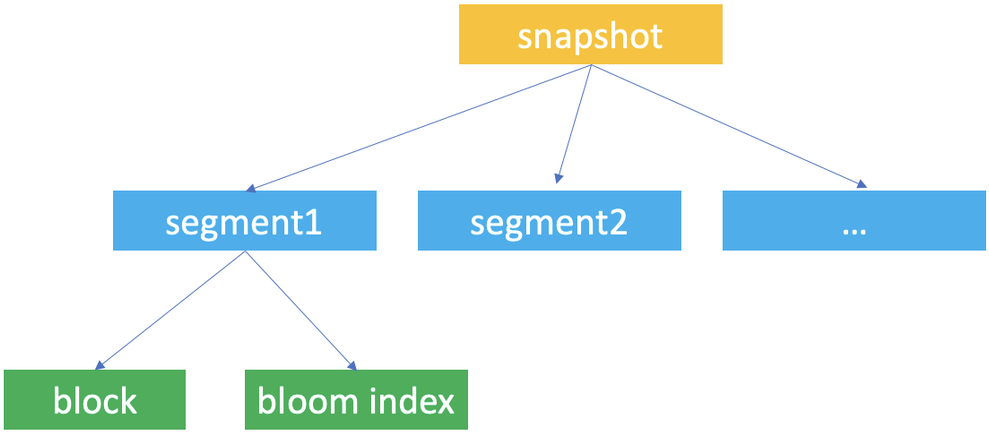
Databend automatically creates snapshots of a table when data updates occur, so a snapshot represents a version of the table's data. When working with Databend, you're most likely to access a snapshot with the snapshot ID when you retrieve and query a previous version of the table' data with the AT clause.
A snapshot is a JSON file that does not save the table's data but indicate the segments the snapshot links to. If you run FUSE_SNAPSHOT against a table, you can find the saved snapshots for the table.
A segment is a JSON file that organizes the storage blocks (at least 1, at most 1,000) where the data is stored. If you run FUSE_SEGMENT against a snapshot with the snapshot ID, you can find which segments are referenced by the snapshot.
Databends saves actual table data in parquet files and considers each parquet file as a block. If you run FUSE_BLOCK against a snapshot with the snapshot ID, you can find which blocks are referenced by the snapshot.
Databend creates a unique ID for each database and table for storing the snapshot, segment, and block files and saves them to your object storage in the path <bucket_name>/[root]/<db_id>/<table_id>/. Each snapshot, segment, and block file is named with a UUID (32-character lowercase hexadecimal string).
| File | Format | Filename | Storage Folder |
|---|---|---|---|
| Snapshot | JSON | <32bitUUID>_<version>.json | <bucket_name>/[root]/<db_id>/<table_id>/_ss/ |
| Segment | JSON | <32bitUUID>_<version>.json | <bucket_name>/[root]/<db_id>/<table_id>/_sg/ |
| Block | parquet | <32bitUUID>_<version>.parquet | <bucket_name>/[root]/<db_id>/<table_id>/_b/ |
Table Optimization Considerations
Consider optimizing a table regularly if the table receives frequent updates. Databend recommends these best practices to help decide on an optimization for a table:
When to Optimize a Table
A table requires optimization if more than 100 blocks of it meet the following conditions:
- The block size is less than 100M.
- The number of the rows in the block is less than 800,000.
select if(count(*)>100,'The table needs compact now','The table does not need compact now') from fuse_block('<your_database>','<your_table>') where file_size <100*1024*1024 and row_count<800000;
Compacting Segments Only
The optimization merges both segments and blocks of a table by default. However, you can choose to compact the segments only when a table has too many segments.
Databend recommends optimizing the segments only for a table when the table has more than 1,000 segments and the average number of blocks per segment is less than 500.
select count(*),avg(block_count),if(avg(block_count)<500,'The table needs segment compact now','The table does not need segment compact now') from fuse_segment('<your_database>','<your_table>');
When NOT to Optimize a Table
Optimizing a table could be time-consuming, especially for large ones. Databend does not recommend optimizing a table too frequently. Before you optimize a table, make sure the table fully satisfies the conditions described in When to Optimize a Table.
Syntax
-- Purge historical data
OPTIMIZE TABLE [database.]table_name PURGE
-- Purge historical data generated before a snapshot or a timestamp was created
OPTIMIZE TABLE [database.]table_name PURGE BEFORE (SNAPSHOT => '<SNAPSHOT_ID>')
OPTIMIZE TABLE [database.]table_name PURGE BEFORE (TIMESTAMP => '<TIMESTAMP>'::TIMESTAMP)
-- Compact historical data
OPTIMIZE TABLE [database.]table_name COMPACT [LIMIT <segment_count>]
-- Compact historical data by merging segments ONLY
OPTIMIZE TABLE [database.]table_name COMPACT SEGMENT [LIMIT <segment_count>]
-- Compact and purge historical data
OPTIMIZE TABLE [database.]table_name ALL
OPTIMIZE TABLE <table_name> PURGEPurges historical data from the table. Only the latest snapshot (including the segments and blocks referenced by this snapshot) will be kept.
OPTIMIZE TABLE <table_name> PURGE BEFORE (SNAPSHOT => '<SNAPSHOT_ID>')Purges the historical data that was generated before the specified snapshot was created. This erases related snapshots, segments, and blocks from storage.
OPTIMIZE TABLE <table_name> PURGE BEFORE (TIMESTAMP => '<TIMESTAMP>'::TIMESTAMP)Purges the historical data that was generated before the specified timestamp was created. This erases related snapshots, segments, and blocks from storage.
OPTIMIZE TABLE <table_name> COMPACT [LIMIT <segment_count>]Compacts the table data by merging small blocks and segments into larger ones.
- This command creates a new snapshot (along with compacted segments and blocks) of the most recent table data without affecting the existing storage files, so the storage space won't be released until you purge the historical data.
- Depending on the size of the given table, it may take quite a while to complete the execution.
- The option LIMIT sets the maximum number of segments to be compacted. In this case, Databend will select and compact the latest segments.
OPTIMIZE TABLE <table_name> COMPACT SEGMENT [LIMIT <segment_count>]Compacts the table data by merging small segments into larger ones.
- See Compacting Segments Only for when you need this command.
- The option LIMIT sets the maximum number of segments to be compacted. In this case, Databend will select and compact the latest segments.
OPTIMIZE TABLE <table_name> ALLEquals to
OPTIMIZE TABLE <table_name> COMPACT+OPTIMIZE TABLE <table_name> PURGE.
Examples
-- Create a table and insert data using three INSERT statements
create table t(x int);
insert into t values(1);
insert into t values(2);
insert into t values(3);
select * from t;
x|
-+
1|
2|
3|
-- Show the created snapshots with their timestamps
select snapshot_id, segment_count, block_count, timestamp from fuse_snapshot('default', 't');
snapshot_id |segment_count|block_count|timestamp |
--------------------------------+-------------+-----------+---------------------+
edc9477b62c24f299c05a4d189030772| 3| 3|2022-12-26 19:33:49.0|
256f1fe2e3974ee595474b2a8cad7a39| 2| 2|2022-12-26 19:33:42.0|
1e060f7d145747578963b5a7e3b14742| 1| 1|2022-12-26 19:32:57.0|
-- Compact the table table
optimize table t compact;
-- Notice that a new snapshot was added
select snapshot_id, segment_count, block_count, timestamp from fuse_snapshot('default', 't');
snapshot_id |segment_count|block_count|timestamp |
--------------------------------+-------------+-----------+---------------------+
9828b23f74664ff3806f44bbc1925ea5| 1| 1|2022-12-26 19:39:27.0|
edc9477b62c24f299c05a4d189030772| 3| 3|2022-12-26 19:33:49.0|
256f1fe2e3974ee595474b2a8cad7a39| 2| 2|2022-12-26 19:33:42.0|
1e060f7d145747578963b5a7e3b14742| 1| 1|2022-12-26 19:32:57.0|
-- Purge the historical data generated before the new snapshot was created.
optimize table t purge before (SNAPSHOT => '9828b23f74664ff3806f44bbc1925ea5');
select snapshot_id, segment_count, block_count, timestamp from fuse_snapshot('default', 't');
snapshot_id |segment_count|block_count|timestamp |
--------------------------------+-------------+-----------+---------------------+
9828b23f74664ff3806f44bbc1925ea5| 1| 1|2022-12-26 19:39:27.0|
select * from t;
x|
-+
1|
2|
3|