Tutorial - Load from an Amazon S3 Bucket
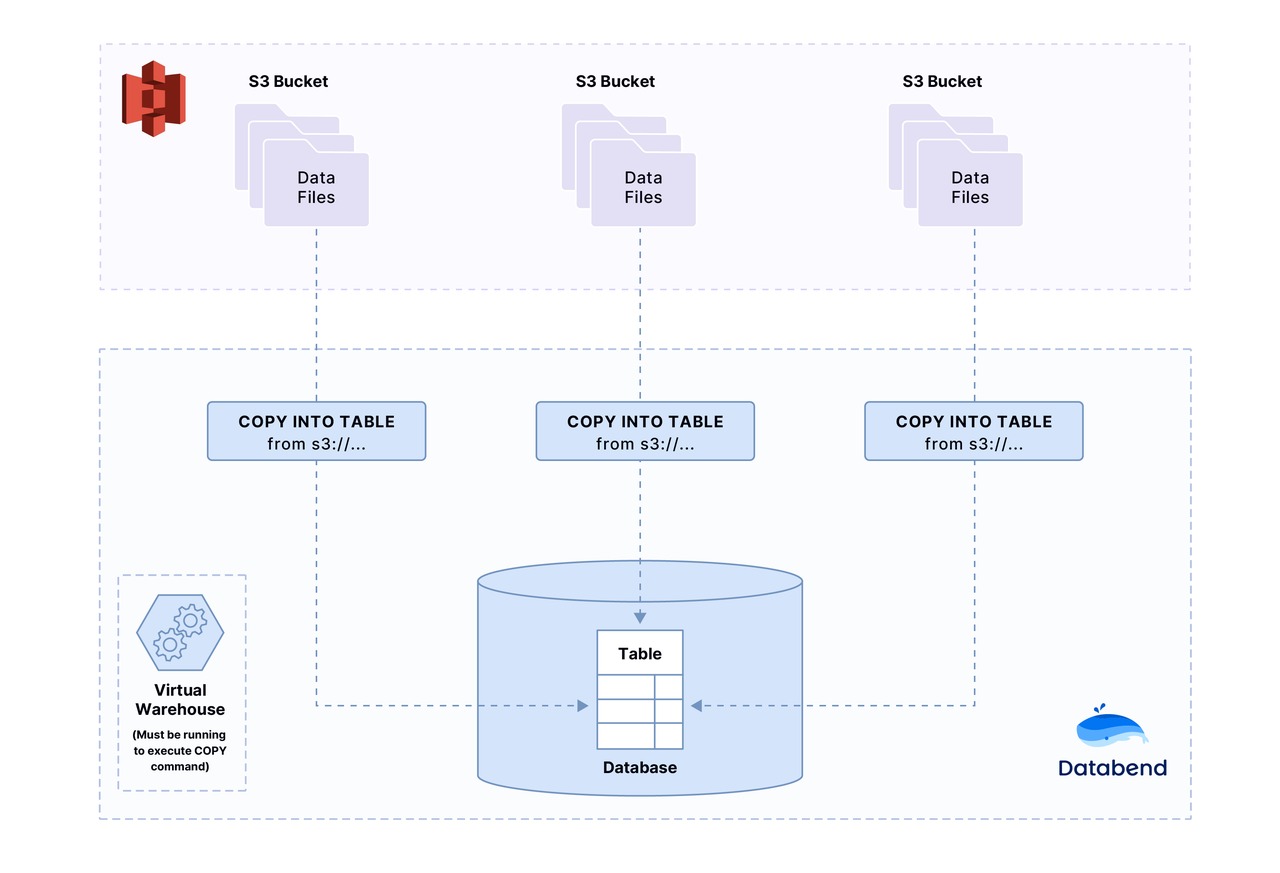
In this tutorial, you will upload a sample file to your Amazon S3 bucket, and then load data from the file into Databend with the COPY INTO command.
Step 1. Data Files for Loading
Download the sample data file(Choose CSV or Parquet), the file contains two records:
Transaction Processing,Jim Gray,1992
Readings in Database Systems,Michael Stonebraker,2004
- CSV
- Parquet
Download books.csv
Download books.parquet
Step 2. Creating an Amazon S3 Bucket
If you don't know how to create Amazon S3 bucket, please see Create Amazon S3 Bucket.
Step 3. Add sample data files to Amazon S3 bucket
Upload books.csv or books.parquet to the bucket.
If you don't know how to upload file to Amazon S3 bucket, please see Upload Files to Amazon S3 Bucket.
Step 4. Create Database and Table
mysql -h127.0.0.1 -uroot -P3307
CREATE DATABASE book_db;
USE book_db;
CREATE TABLE books
(
title VARCHAR,
author VARCHAR,
date VARCHAR
);
Now that the database and table have been created.
In Step 3 of this Quickstart, you uploaded the books.csv or books.parquet file to your bucket.
To use the COPY data loading, you will need the following information:
- The name of the S3 URI(s3://bucket/to/path/), such as: s3://databend-bohu/data/
- Your AWS account’s access keys, such as:
- Access Key ID: your-access-key-id
- Secret Access Key: your-secret-access-key
- Security Token (Optional): your-aws-temporary-access-token
Step 5: Copy Data into the Target Tables
Using this URI and keys, execute the following statement, replacing the placeholder values with your own:
- CSV
- Parquet
COPY INTO books
FROM 's3://databend-bohu/data/'
credentials=(aws_key_id='<your-access-key-id>' aws_secret_key='<your-secret-access-key>' [aws_token='<your-aws-temporary-access-token>'])
pattern ='.*[.]csv'
file_format = (type = 'CSV' field_delimiter = ',' record_delimiter = '\n' skip_header = 0);
COPY INTO books
FROM 's3://databend-bohu/data/'
credentials=(aws_key_id='<your-access-key-id>' aws_secret_key='<your-secret-access-key>')
pattern ='.*[.]parquet'
file_format = (type = 'Parquet');
If the file(s) is large and we want to check the file format is ok to parse, we can use the SIZE_LIMIT:
COPY INTO books
FROM 's3://databend-bohu/data/'
credentials=(aws_key_id='<your-access-key-id>' aws_secret_key='<your-secret-access-key>')
pattern ='.*[.]csv'
file_format = (type = 'CSV' field_delimiter = ',' record_delimiter = '\n' skip_header = 0)
size_limit = 1; -- only load 1 rows
Step 6. Verify the Loaded Data
Now, let's check the data to make sure data has actually loaded:
SELECT * FROM books;
+------------------------------+----------------------+-------+
| title | author | date |
+------------------------------+----------------------+-------+
| Transaction Processing | Jim Gray | 1992 |
| Readings in Database Systems | Michael Stonebraker | 2004 |
+------------------------------+----------------------+-------+